
Cloud Transformation & Technical Debt
A Cloud Transformation programme can reverse years of underinvestment, and turn technical debt into technical wealth. But it's not as simple as asking IT to sort out the technology. This is a whole company transformation that needs to embrace all parts of our message on Digital Transformation.

Many organisations have a Cloud First policy, a very sensible intent to move their applications and infrastructure out of data-centres and into the Cloud.
Digital mastery is achieved from a combination of digital capability and leadership capability and is implemented by an ongoing digital transformation initiative which will typically include, alongside the organisational and behaviour change programmes, several digitalisation programmes, the most important of which is concerned with removing technical debt by transforming legacy technology onto Cloud Services.
The Exec Committee duly set up a Cloud Transformation programme and eagerly wait for the the good news that it's progressing well and is on track to finish. How hard can it be?
Let's take a look at some of the key considerations.
Application Landscape
In order to run their business, many organisations have a significant number of applications - which are used as systems of engagement or systems of record:
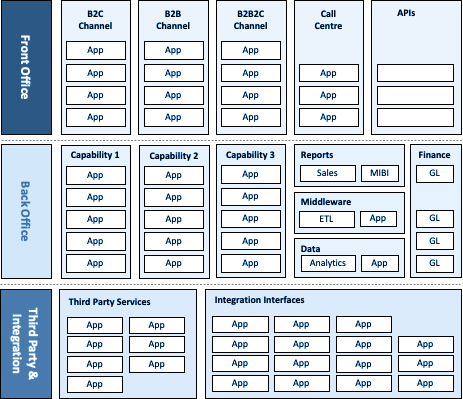
The trouble is that, over time, many of these applications aren't quite as purposeful as they once were. Quite rightly, the organisation has grown, and responded to changes in the market, in technology and in consumer preference. What started out as a neat set of applications, each with a specific purpose, is now a mish-mash of essential, helpful, part-used and pointless systems.
In reality everything is a mess of M&A, wishful thinking, half-finished projects and shadow IT, but it gets worse ...
You could say that a lack of enterprise architecture is to blame, but there are always points in a company's existance when it has to just go for it, and then tidy up afterwards. But, without an iron dicipline, the next essential push comes, and its far more interesting to work on the shiny new stuff than is is to sift through yesterdays' work, so it gets forgotten.
This situation rears its head again when it becomes imperative to make a change to one of the legacy applications. Instructions are given, but developers report that the code is so complex and intertwined that, whilst they think they have made the changes necessary, it should be thoroughly tested before going live - because, anecdotally, one-third of all annual revenue is variously channelled through it ...
At this point, colleagues are asked to find the testing harness, and to get in touch with the business owner to let them know what's happening.
You're ahead of me here. The orginal business owner of the application left two years ago, and her successor was never told of that responsibility. And no one can find the testing harness - if one ever existed. Further enquiry reveals that the Application Support team did have a handover when then application went into production, and a Runbook exists on the company intranet. Relief turns to frustration when perusal of the Runbook reveals nothing more than a few fatuous or obvious statements, with no summary of why things were done in a certain way, a list of the integrations, or suggestions of things to watch out for. Happily, the Support Analyst named in the Runbook is still working for the company, but, rather unhelpfully, doesn't recall ever having had to amend that particular application, so doesn't have any up to date knowledge of it. Hmm.
Technical Infrastructure
Each application runs on technical infrastructure. Most business people only see the user interface, the part of the application that they and the company's customers interact with. In simple terms, that application needs to sit on a server somewhere, in order to be able to operate, and to have its pages served to the user. Most applications exist to capture, display or amend information, and the data that is manipulated by the application has to sit on another server, and travel to and from the application, as required in order to meet the business functionality.
This infrastructure - let's call it servers and networks - is a mixure of hardware and system software (the intelligence that tells the hardware what to do). Just like business applications, the system software will age and hardware will, eventually, fail.
Think of the car you drive. You buy it to achieve a purpose - transporting you around - and you don't really need to know what goes on underneath. You are encouraged to keep it maintained of course, but there comes a point when parts fail, and it becomes costly and harder to keep it going. You could sell it and buy a new car, knowing that you'll have fixed monthly costs and a reliable product for the next few years, as well as the latest features. But you don't have the cash for a deposit, so you make your asset work a little harder and hope that it won't let you down. That's the approach many companies take with their technology.
The car analogy illustrates how end-users or external customers really don't care about maintenance, because the best possible maintenance leaves the system in the same state as before, from a user perspective. Technology teams need to be very good at stakeholder management, sales and marketing to deal with this lack of visibility.
The trouble with this approach is that the company begins to incur technical debt. IT should have spent some money, but didn't, and accepted the trade off instead. Hey, nothing bad will happen? Right?
Short-term short-cuts generate long-term work that costs more to rectify the longer it's left.
The thing is, yes, it probably still works and its unlikely to stop working tomorrow. But Microsoft stopped supporting the system software version that your servers and databases are running on last year, and your network infrastucture is at end-of-life. If one of your aged infrastructure hardware switch fails, then its now impossible to buy a new one, and your Infrastructure Team will need to trade in the second-hand market for the part. If system software is not supported, then security vulnerabilities can be exploited by organisations unknown.
Your B2B clients will have a clause in their contract with you that says that you must run all the applications that you use to provide their service on infrastructure that is within manufacturer support. The regulator in the majority of countries that you do business in will insist on the same thing. Your PCI compliance will be at risk and your external auditors will have written a management letter requiring mitigation.
And we haven't even considered the state of your disaster recovery setup. If the production service has been neglected, then its likely that your ability to continue business in the event of a serious event will also be compromised. Has it been thoroughly tested recently?
A definition of Technical Debt
The application turns out to be an impenetrable block of code, with little meaningful documentation, no ability to test that the orginally intended business outcomes still happen, no one to take responsibility for it - and, it seems that if it goes wrong then corporate revenue flow could be affected. Ouch.
Your technical infrastructure is end-of-life, and worse, is not being patched to protect your company from cyber incursion. Not only could the basis of your revenue fail at any moment, your company is in contractual and regulatory denial, and at risk of a significant fine.
All of this has happened because of the growth of technical debt.
A definition? From a technical infrastructure perspective, technical debt is about staying within manufacturer support. When Microsoft announced that support for SQL2012 R2 or Windows 2012 R2 ceased on a certain date, you had better make sure that your applications can run on MS2016, or better still on MS2020, and that you've spent money on the licences and the support.
From an application perspective, technical debt is about being able to properly and completely test the application and its interfaces to other applications. With no test-harness to prove outputs, the application is a major risk to business operations. Don't think that technical debt is only relevant to legacy code either. With no ability to test, no contextual documentation to explain the business and technical decisions at the time, or a lack of understanding as to why a developer coded the way they did, then you've got technical debt, even if the code is onlhy a few months old. Without the correct mindset and information, your flagship new system can be creating technical debt right now.
Taken together, technical debt arises because the organisation is unwilling to spend money, or is not spending it on the correct thing. Like financial debt, the interest charged is limiting your ability to move ahead. You need to reduce it.
Time and Technical Debt
Technical debt is like compound interest. Unless you pay it down, it gets greater every year. And every year, you can achieve less with the same resources.
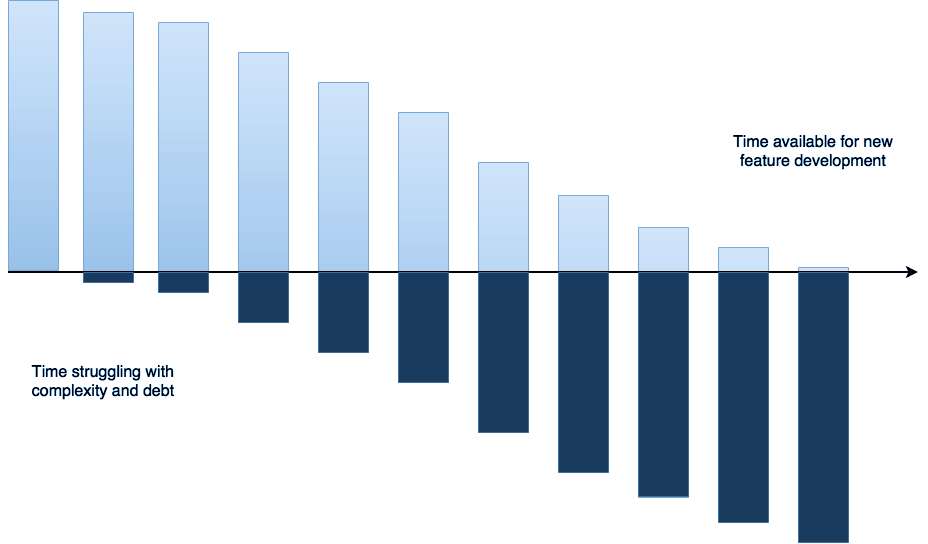
When the CEO starts asking "why wasn't that promised feature ready on time" and "why aren't your people more productive", the answer is probably that the culture of the company is working against you. Changing the overall attitude toward investing in maintenance and modernisation is the place to start, ideally at the top.
Back in the day, whenever a change was proposed to an application or the infrastructure it ran on, then the reasons for the proposal were considered and, if everything checked-out, the green-light given to go ahead. At the time, the decision was made based on the information to hand, the problem or opportunity itself and the way the business world was then. All done properly.
Fast forward to today.
Systems that were once considered secure, compliant and in support may no longer be. Every software system has bugs, some of which have cyber-security consequences. As time passes, more of these bugs are found, leading to code change and more bugs... Cyber threats are considerably more evident and responded to than in the past; these days security is designed into a new application, but new software isn't necessarily more secure than old software.
Data protection laws have made it a significant offence to hold unencrypted personally indentifiable data (PII) or credit card primary account numbers (PAN), and in any case, every company must have good reason to keep data and is obliged to take care of it. This wasn't always the situation, and legacy systems of record may not have been updated in line with legislative changes.
Country regulators may since have ruled that data on their citizens cannot leave their country. You may find that your team changed the relevant application to store data within an accredited data centre within that country, but you later realise that no-one noticed that the back-up copy is still in the UK or US disaster recovery site.
When a top-10 client negotiated a revised B2B2C agreement when your company was reappointed for another 3 years, it instigated a contractual change that requires that data relating to its clients be kept separate from the clients of your other B2B2C business. But Legal didn't pass on that message.
You realise that you've been retaining customer data for longer than 6 years, and need to amend the relevant applications to regularly delete the archive, to ensure that data retention law is not broached. But then you realise that the same application processes data in one country when the requirement is 5 years, and another when it is 7 years.
What do you do? Your applications aren't in any fit state to respond to these imperatives. But your compliance team could go to prison, and your Commercial Director says that 3 major clients are threatening to pull their business. And the non-executive directors are threatening to resign.
Taking Action
Technical debt isn't necessarily a completely bad thing, just like borrowing money to invest in future growth. It might not make sense to test your new application extensively when you’re heading towards a minimum viable product. But once you have that product out in the market, and your customers are seeing some value, then you need to start investing in maintenance and incremental improvements. If you are always focused on adding features then you'll get a point when you cannot scale.
It’s hard to convince your peers to spend on fixing something that is already working. But if your company doesn't address technical debt until it takes 3 months to do something that used to take 3 weeks, then it can be very expensive to pay down.
When you resolve debt, it feels good, and you give yourself momentum. You'll gain productivity and reduce risk. Far better to look at what is holding your existing team back, than hiring hot-shot newbies to work their magic... until they get institutionalised, and can't. Central to this is that all code is messy, buggy, barely functional, difficult to maintain and riddled with regret. You have to take the hard path and keep software maintained properly, by implementing processes that allow for that. For example, dedicating a set percentage of time to tech debt tasks in each sprint, or horizon scanning for support expiry dates, so you have enough time to react. If you focus on removing the reasons for technical debt, then you'll be building technical wealth.
This is a critical mindset shift. Stop doing the things that create technical debt and start doing the things that build technical wealth.
Pre-requisites for Technical Wealth
You can't scope a programme of work to remove technical debt if you don't know the extent of your technology estate. Normally there is - or should be - a top-down Enterprise Architecture view, and a bottom up IT CMDB view. Experience indicates that both are likely to be incomplete, inconsistent or wrong. And there is usually no cross-reference between them, or to business operations.
All applications, their purpose and their longevity must be known. Any compliance, risk, security, legal or architectural challenges associated with each application must be known.
There should be an architecture derived Product Roadmap that sets out the functional capabilities of the main revenue earning applications, typical revenue generated, and is clear on their likely remaining life. This should be extended to all legacy systems, including those not obviously being replaced by any new capability, in order guide action on renewal or retirement.
All of the key contact names for an application should be known - IT Owner, IT SMEs, Business Owner, Business SMEs, all key external partner names, IT contacts at external partners. The business and IT owners must accept their ownership.
Every legal agreement with each client, partner and supplier must be made available and be easily accessible.
For each contract, there should a clear view of obligations and restrictions, including, for example, flow down audit requirements or any requirement to run in-support infrastructure. Ideally, the risk within the entire contract base should be known and monitored. Every programme of work will be asking the same questions, so if makes sense to invest in answering them.
If you operate in a regulated industry or in multiple jurisdictions, there must be a list of regulated entities with the relevant regulator named and contactable. The explicit requirements of each regulator should be known.
Each corporate service used by clients and/or partners should be explicitly known, as should the applications and technical infrastructure used to provide each service. As should the Suppliers of any externally provided capability.
The revenue and profit generated through and by each service, and therefore the applications and technical infrastructure used to provide each service - a flow of how the money is made through the chain of applications should be available.
The revenue and profit generated through and by each external partner should be known, and triangulated back to the services that they consume.
Each application must have a data flow diagram to be GDPR compliant.
Data should be rationalised so that there is no data contained in an on-premise databse that is over retained before it is moved to a Cloud database.
Data should be physically segregated where there is a contractual requirement to do so. Application architecture may need to be revisited.
All of the above should be stored in an easily accessible Corporate Knowledge Management tool, and kept up to date.
Then, as you get going, for each application:
- Make sure that artefacts exist that explain the engineers' thinking and make it easier to understand the context of development in the future
- Refactor the code base to remove monoliths and aim for microservices
- Refactor the code base so that it runs on the latest version of server and database system software, and is fully within manufacturer support.
- Decouple features to make them more extensible
- Establish automated testing, so that code validates itself.
The way the company is organised must move to a target operating model, with the Cloud Transformation programme owning a cross-functional engineering team.
Unless the programme director fully owns the resource and gains the Exec's permission to change the company operating model, the programme will be held back.
In short, success relies on the implementation of a Product-Led organisational structure with Enterprise Architecture, Product Management and Engineering; and follow the Three Laws of the Customer, Small Team and Network.
There must be a fully formed Programme Control team in place, reporting to the Programme Director, before the programme starts in earnest. This includes a dedicated Infrastructure Architect, Legal Counsel, Compliance and Risk Advocate, Cyber Security Advocate, Communications and Engagement Manager, plus a Cloud Cost Modeller, Finance Business Partner and a dedicated PMO.
Each corporate function must be adequately resourced to answer requests from the programme, and to participate in projects that require their specific expertise, such as data retention, architectural direction, contract enquiry, new contract letting, etc.
Cloud Transformation is not an IT transformation. It must start with business process change, to rationalise systems and simplify the application landscape. Then cloud technologies can be used to facilitate or accelerate changes, as well as bring debt-ridden systems into compliance again.
Start the Cloud Transformation Programme
It's tempting to treat the removal of technical debt as an IT responsibility, and it may be that the CIO is the sponsor of the programme. But it's not as simple as asking IT to sort out the technology. The reason that the technical debt has arisen is largely for non-IT reasons. This is a whole company transformation that needs to embrace all parts of our message on Digital Transformation.
So, with that caveat, we can move ahead.
Approach
Once all of the applications and infrastructure are understood and the enabling work has been done, then the six common strategies for transformation to the Cloud (6Rs) can be used as the basis for deciding what to do with each application.
[ Remember that we're now getting into the nuts and bolts of transformation work, but it's a system-level view, whereas the real pain is political. ]
- Lift & Shift (Rehost). When an application is simply rehosted in the Cloud without any transformation (aka migration).
- Lift & Reshape (Replatform). Where the core architecture of the application is retained, but the underlying infrastructure is replaced by appropriate cloud services.
- Drop & Shop (Repurchase). This applies to applications which could be provided by a SaaS vendor.
- Transform (Refactor). The Product Roadmap will suggest what products should be rebuilt as cloud-native applications, especially those that are strategicand will produce significant commercial benefits.
- Decommission (Retire). Where there is minimal commercial benefit and no wish to invest.
- Retain. An application which still has a business purpose, and which needs to stay on premises.
You would only Rehost if time were against you, because this approach this moves risk too, which justs kicks the can down the road.
Some applications can be Repurchased; in the years since the current legacy application was bought, new offerings have come to market. This will almost certainly include MS Office and MS AD identity, a major programme in its own right.
A significant number of applications should be Retired; only those with a revenue contribution greater than an agreed value should be kept, as well as those which as required for regulory purposes or which make a positive contribution to reputation.
There should be no applications Retained in an on-premise data centre. Time has provided a cloud-version of just-about everything. If certain senior leaders make a case for retention, and equally strong case can be made to move it.
Where merger or acquisition has resulted in several similar applications, with over-lapping functionality then it makes sense for the company to either buy a SaaS solution or, if it is a commerically competitive differentiator, then to Refactor - to build a brand new application in the Cloud.
The applications left are then the candidates for Replatforming onto cloud infrastructure. It is vital that the pre-requisites activities have been completed or it will be found that each suffers from a compelling risk that prevents it moving.
In addition to the applications, there will be a considerable number of orphan servers that can be Retired (for example, old test environments) or rebuilt in the Cloud (for example, telephony servers).
Preparation
A number of signifcant activities precede the actual Cloud transformation:
- The Portfolio Analysts will prepare documentation to guide the Implementation Squads' technical tranformation activities.
- The strategic home for the company's applications in the Cloud must be architected and the design detail of each theme agreed.
- Standards for Cloud Infrastructure must be created to advise engineering teams building new systems how to use the new Cloud services
- A cost model must be designed such that it will be possible to model the likely future operational expenditure associated with each design pattern.
- Exising maverick spend on Cloud services must be identified and consolidated.
- Inappropriate historic 'check box' Terms and Conditions which exist must be renegotiated into an appropriate enterprise agreement, allowing audit and generating volume discount.
Implementation
Once the pre-requisites and the design activities have been completed, then multiple engineering teams, each a cross-functional 'small' team working in 2-week sprints will start the 6R activity. Each team will include staff from architecture, product, business ops, cyber security, IT development, IT suppport and IT infrastructure and will self-direct and follow agile ceremonies.
All implementation teams must work under the programme, as an operational entity, with individuals ring-fenced and released from supporting their functional teammates. Once these teams have achieved cloud transformation, they remain in post and become the organisation team responsible for those products.
This is hugely important: a) it ensures that the programme has the resources it needs to succeed, b) it pivots the organisation though 90° to be cross-functional and c) it moves the company away from capex funding and to operational expenditure.
Method
In general, each team will follow this method:
One of these teams focuses on building the strategic cloud infrastructure, and iteratively improving its capability and hardening its security. The other engineering teams take on product backlogs based on the 6Rs backlog, and work their way through the transformation. Crucially, they retain responsibility for the maintenance of each application once they have put it into production.
The teams interate through their product backlogs in successive sprints, constantly delivering. Over time, as they have transformed their products, they will begin to receive new requests to enhance functionaility or to deal with a fault, and they will assume the status of a Squad.
Benefits
Let's not forget that this is not a simple technology programme, with a straightforward business case. This is a whole company initiative and is best done as part of the whole digital mastery initiative.
The Exec Committee must be fully engaged and fully committed, and the work must be properly funded. If your CFO baulks at the cost, then remember that this journey is about transitioning your company to be wholly customer-centric. It's about staying relevant and its about staying in business.
So... no need to talk about a particular ROI, although a busines case could be built. This work is essential to your company's future success.
Nevertheless, some of the benefits that your organisation may look foreard to include:
You will probably need help you set up and run a Cloud Transformation programme, to turn your technical debt into technical wealth.
Within the overall business-led initiative, any tech migration service might be as follows:
- Discovery. Data-driven discovery of your full IT estate and commentary on its complexity.
- Costing. Cost comparison matching your IT estate to equivalent leading cloud providers showing what detailed servers and infrastructure you would need to purchase to match your current service.
- Patterns. Complete cost and bill of materials with equivalent performance statistics for each provider for different scenarios.
- Rationalisation. Data-driven architectural planning and simplification.
- Migration. Migration of applications to a new cloud provider with implementation of associated change across the organisation.
- Optimisation. Your IT Operations team need to learn how to manage your cloud services, optimise costs and secure your cloud infrastructure.
Next
Many of the themes touched on in this post are taken further in other articles:
 David Seacombe
David Seacombe David Seacombe
David Seacombe David Seacombe
David Seacombe
Postscript: Capex vs Opex
Its worth considering the impact of moving from one-off capital expenditure to ongoing operational expenditure, based on usage.
Reducing technical debt may be achieved by moving systems that are hosted in on-premise data centres to infrastructure provided by public cloud services such as MS Azure, GCP or AWS. These are on-demand services and are paid for as the services are consumed.
The Capex-based business model:
- Requires upfront capital investment in service assets (higher cashflow requirements)
- Increases future years' Opex as depreciation charges increase due to the new Capex
- Reduces flexibility as assets cannot be changed before their end-of-life without a significant write-off and impact on the P&L
- Reduced flexibility could also result in a sub-optimal service platform
- Reduction in service capacity does not necessarily lead to a reduction in Opex, as the asset cost has been incurred fro the life of the asset
- Higher fixed costs (Capex) increases the break-even point at which profits are made.
Moving to an Opex-based Cloud business model:
- Requires little or no capital investment (lower cash-flow requirements)
- Reduces/eliminates depreciation charges to the P&L for service assets
- Increases flexibility as capacity can be reduced or increased with service demand, with a corresponding change in Opex
- Eliminates the threat of being tied to a sub-optimal service platform
- Reduces fixed costs (Capex) and so lowers the break-even point at which profits are made.
Implications of a move from Capex to Opex
- A Cloud Transformation programme will initiate purchase of Cloud Services rather than physical assets
- The move from an asset-purchasing to a service-purchasing way of working will change the recognition of the expense within the company P&L, with a decline in depreciation being offset by an increase in Opex/IT services
- This will change expense recognised within EBITDA (Opex - IT services) and below the line (depreciation/amortisation), and so you should anticipate an impact on performance measurement criteria.
Make sure that you adjust how your Exec Committee are incentivised in an Opex world.